AI 视频生成目前正处于从“概率抽卡”向“精准生产”转型的关键期。其底层逻辑是利用扩散模型(Diffusion Models)或自回归模型(Autoregressive Models)预测像素在时间轴上的连续变化,从而模拟物理世界的视觉规律。到 2026 年 3 月,该技术已能支持复杂叙事与实时编辑,但核心矛盾依然是:生成质量的上限极高,而可控性的下限仍不稳定,角色服装颜色在切镜时跳变、背景建筑缓慢形变等问题依然存在。
技术原理解析:DiT 架构如何模拟物理世界
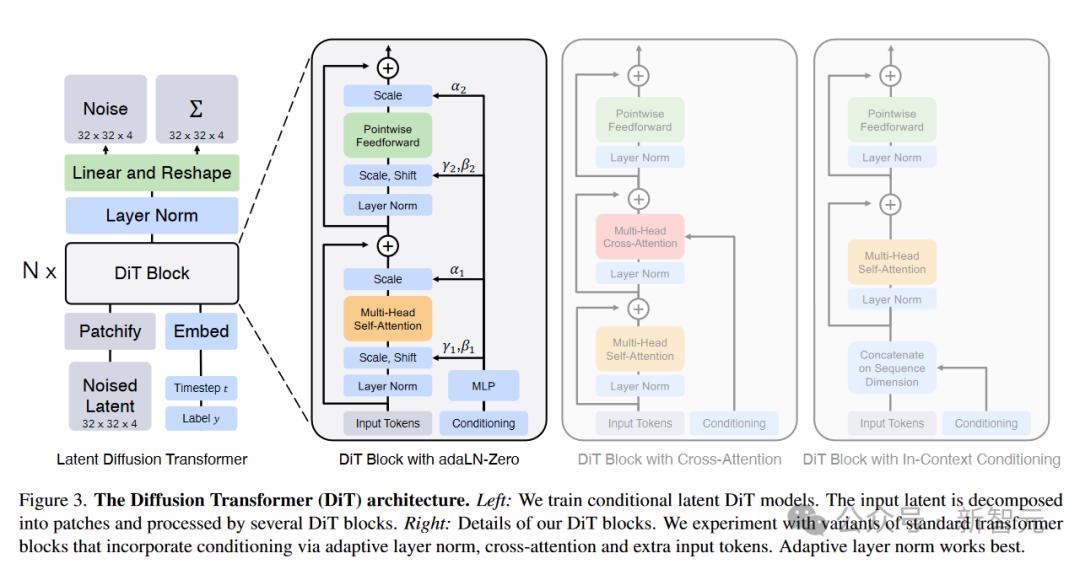
当前顶级模型均基于 DiT(Diffusion Transformer)架构,实现了从像素平移到物理规律理解的跨越。 该架构将视频切分为“时空补丁”(Spacetime Patches),在潜空间(Latent Space)中同步处理空间与时间维度。相比早期的逐帧预测,DiT 能够理解物体在重力作用下的抛物线轨迹,而非简单的像素平移。
高质量视频的产出依赖三个阶段的训练:首先通过数亿量级的视频片段进行预训练以建立物理常识;其次通过文本对齐训练,使模型识别“低角度跟拍”等专业电影指令;最后通过 RLHF(人类反馈强化学习)剔除违背物理直觉的形变。
在实际操作中,具体的物理描述比形容词更有权重。与其使用“震撼的、高分辨率的”等空泛词汇,不如描述“光线从左侧 45 度射入,尘埃在丁达尔效应中漂浮”,后者更容易触发模型的高质量权重。
2026 年主流工具实测对比

不同工具在物理模拟、一致性与生成效率之间存在明显的侧重差异。 开发者在选择工具时应基于具体项目需求(如商业广告 vs 社媒短内容)进行匹配。
| 工具名称 | 核心优势 | 主要局限 | 适用场景 |
|---|---|---|---|
| Kling 2.6 | 物理模拟顶尖,材质还原度极高 | 高峰期生成速度较慢 | 商业广告 Demo |
| Sora 2 | 长视频一致性强,运镜专业 | 细节处理过于平滑,有 3D 感 | 长叙事电影感短片 |
| Wan 2.6 / HAILUO | 迭代速度快,艺术风格多样 | 超长镜头易出现逻辑断层 | 社媒短视频/二次元 |
| Higgsfield / OpenArt | 门槛低,模版化可控性强 | 原生生成上限相对较低 | 非专业人员快速出片 |
商业级短片创作实操指南

采用“分镜控制法”替代长 Prompt 是一次性产出高质量视频的关键。 不要试图用一段长 Prompt 直接生成长视频,而应将过程拆解为可控的步骤:
局限性与适用边界
AI 视频并非万能,在需要极端物理精准度或品牌一致性的场景中,仍需依赖传统管线。 以下三类场景建议维持实拍或 3D 建模:
- 微秒级物理交互: 如手指在钢琴键上快速弹奏,AI 难以实现肌肉抽动与触点同步,常出现穿模。
- 绝对细节一致性: 如要求角色衣服上的特定污渍在 10 分钟视频中位置不变,AI 仍会发生漂移。
- 严苛的品牌 VI 约束: 产品 Logo 在动态旋转中不能有 1% 的形变,建议采用“AI 背景 + 3D 精准模型”的合成方案。
法律风险与未来演进
版权问题仍处于灰色地带。以 Veo 3 为例,因训练集包含大量受保护素材,若生成的画面与知名电影镜头过于相似,易被判定为侵权。建议采取“混合链路”策略:AI 生成氛围底图,核心主体使用自有版权素材叠加。
未来 12 个月,AI 视频将向“实时交互”演进。 生成逻辑将从“输入 $\rightarrow$ 等待 $\rightarrow$ 导出”变为“实时预览 $\rightarrow$ 实时调整”。同时,视频生成将与 3D Gaussian Splatting 融合,使 AI 从生成像素转向生成可交互的 3D 空间。
如何有效降低 AI 视频中的“闪烁”或“形变”感?
核心在于控制“运动幅度”(Motion Strength)并在图生视频(I2V)流程中固定首帧。此外,通过较低的重绘强度(Denoising Strength)进行局部修正,而非全图重新生成,能显著提升视觉稳定性。
对于商业项目,如何确保多镜头之间的角色一致性?
建议建立“角色参考库”。先生成一张高质量且细节丰富的角色静态图,在后续所有镜头中将其作为 Image Prompt 引用,并尽量在同一 Seed 值附近进行微调,以维持面部特征的一致。
行动建议
决定成品质量的不再是 Prompt 技巧,而是审美与叙事能力。 建议从 15 秒的微小项目入手,完整走一遍“图生视频 $\rightarrow$ 局部重绘 $\rightarrow$ 后期剪辑”的链路,将 AI 作为提升生产力的工具而非替代方案。